Using Redis to Cache a List in Production

Users can create a task in a Parabol meeting and send it to a variety of external task management services, such as GitHub, Jira, and Azure DevOps. When a user opens the task card menu, we want to quickly show them all of the GitHub repos, Jira projects, Azure projects, etc, they have available, so they can send their new task to the correct one.
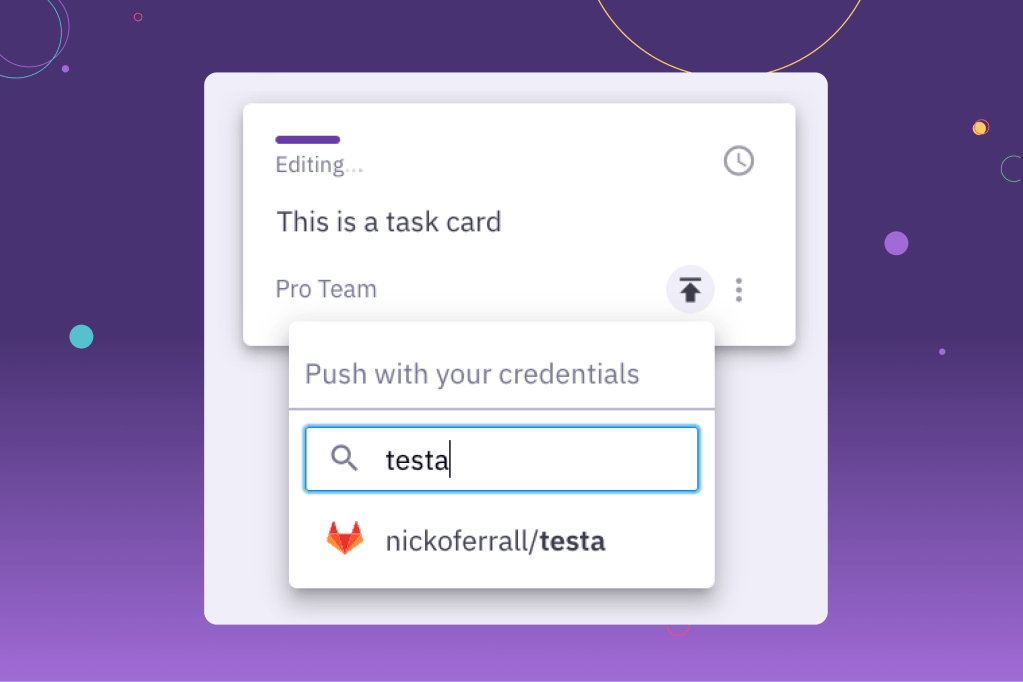
The difficulty is we currently offer five different services users can pull their tasks from, including GitHub, Jira, Jira Server, GitLab, and Azure DevOps. And we’ve got more coming soon.The challenge at hands is how to keep the Parabol app quick and responsive as the number of integrations grows.
When a user opens the menu to push a task to an integration, we reach out to all of the different APIs. If any of them take a while to respond, the user has to wait around looking at a loading spinner.
However, our Growth team discovered that if users activate integrations, they’re significantly less likely to churn, so it’s important that this menu populates as quickly as possible.
Solving the issue with two Redis caches
To speed up the query, we turned to Redis. Redis is a blazingly fast in-memory data store. It uses a simple key-value method to store data, has low latency, and high throughput.
To solve the issue, we built two Redis caches:
- Previously used integrations, called
prevUsedRepoIntegrations - All available integrations, called
allRepoIntegrations
Now, when the user opens the menu for the first time, we’ll still reach out to the network to grab their integrations, but the next time they open it, we’ll reach out to Redis so the results will immediately render.
The first results at the top of the menu are the previously used integrations, and all other available integrations are displayed below. If a user searches for an integration that doesn’t exist, or if they add/remove an integration, we’ll reach out to the network instead of Redis.
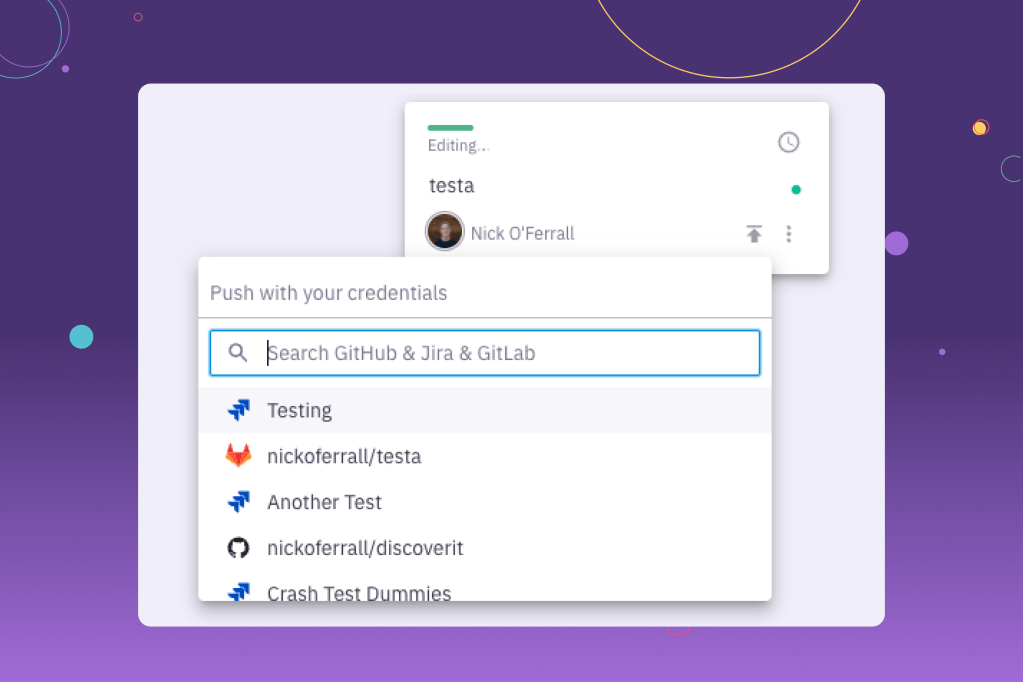
Why create two Redis caches?
After fetching a user’s GitHub repos, for example, we store the response in the allRepoIntegrations cache. However, every user in Parabol belongs to a team, and that team most likely uses the same few repositories.
To save the user from searching through hundreds of repos every time they open the menu, we built the prevUsedRepoIntegrations cache too. When opening the menu, we’d show the previously used repos, and then all of the other integrations.
While we could have sorted allRepoIntegrations to show the previously used integrations first, we opted for two caches because of:
- Simplicity: Redis is a key value store so it’s easy to add the network response to the
allRepoIntegrationskey and then when the user selects a repo, to add it to theprevUsedRepoIntegrationskey. - Time-to-live: If an integration is used in Parabol, there’s a good chance it will be relevant to the team for a long period of time. However, all available repo integrations can become stale much faster as new repositories may be added or removed. With that in mind, we set a 180-day TTL on the
prevUsedRepoIntegrationscache but a 90-day TTL onallRepoIntegrations. - Private vs public repos: The user’s GitHub repositories include both private and public repos. While it’s useful for the user to see all of their repos, just like they can in GitHub, they may not wish to share their private repos with the rest of their team. However, it’s safe to assume that previously used integrations should be accessible to the whole team as they’ve used them before. That’s why we decided to make the
allRepoIntegrationscache team & user specific with the keyallRepoIntegrations:${teamId}:${viewerId}whereasprevUsedRepoIntegrationsis only team-specific:prevUsedRepoIntegrations:${teamId}
Gimme the code for these Redis caches!
Our client can simply send a request to our repoIntegrations endpoint on our GraphQL server, and it’ll handle the caching and network requests:
As you can see, if there are no allCachedRepoIntegrations, such as when the user first opens the menu, or if the client has signalled that we should fetch from the network (we’ll explore this later), we’ll ignore the cache and reach out to the APIs:
We send several requests to the APIs and instruct them to sort by the most recently used repos/projects. We then perform a bit of magic to return the repos in alternating order. We do this because if we showed all of the user’s 50 Jira projects and then all of their 50 GitHub repos, the user will only see their Jira projects in the menu and may wonder where their GitHub repos are.
Once we get the response, it’s time to stringify them and store them in Redis with a 90-day TTL: redis.set(allRepoIntegrationsKey, JSON.stringify(allRepoIntegrations), 'PX', ms('90d')).
The next time the user opens the menu, getAllCachedRepoIntegrations will quickly fetch the results from the cache:
If a user selects one of the repos from the cache, we’ll then add it to the prevUsedRepoIntegrations cache:
For this cache, we use a sorted set with the timestamp as the score. The advantage of this is that we can easily sort by the most recently used repos and adding and removing values is still relatively fast at O(log(N)).
In the code above, we’re checking whether the selected repoIntegration exists in the prevUsedRepoIntegration cache. If it does, we remove it, and then add the new timestamp to the sorted set. To prevent memory leaks and to ensure the cache returns relevant results, we set a TTL of 180-days using pexpire.
We can then fetch the results from Redis in the correct order, like so:
Once we’ve retrieved the data from both caches, it’s time to sort the results:
How do I invalidate the cache?
While the TTLs protect us from memory leaks, how can we make sure the cache isn’t stale? The user may remove their Parabol integration or create a new GitHub repo before the 90-day TTL expires in the allRepoIntegrations cache. We achieve this with two rules:
- Every time the user adds or removes an integration, update the cache
- If the user searches for an integration that doesn’t exist in the cache, use the network
Adding and removing integrations
When we add or remove an integration, we run the following function:
If a user currently has GitHub and Jira repos/projects stored in the cache but then integrates with a new service, such as GitLab, we’ll need to invalidate the allRepoIntegrations cache. By doing this, allCachedRepoIntegrations in the repoIntegrations endpoint (see the first code example) will be null, so we’ll reach out to the GitLab API to get the projects.
If the user then removes their GitLab integration, we’ll filter the allRepoIntegrations cache and then remove any GitLab projects from the prevUsedRepoIntegrations sorted set.
Using the network
If a user searches in Parabol’s menu and no results are returned, it’s possible they are looking for a repository that doesn’t exist in the cache. This happens if the user has added a new repository since we last reached out to the network.
If this happens and the client is sending a request to our repoIntegrations endpoint, we’ll set networkOnly to true which will refresh our cache.
Redis cache saves Parabol up to five API calls
By implementing the two caches in Redis, after the initial fetch, we’re able to save up to five API calls when a user opens the menu. This makes the menu feel fast and snappy, encouraging users to make the most of the integrations we offer.
Everything at Parabol is a work in progress. If you have any suggestions on how we could improve this, we’d love to hear from you!





