#420 – All In On Postgres
Friday Ship #420 | November 8th, 2024

For the last few months, we haven’t been releasing as many features as we usually do. This is because we took a few cycles to focus on the backend stability of our application. More specifically, we migrated our database from RethinkDB to Postgres. In the tech world, database migrations are a necessary part of life. Requirements change, technologies mature, and it was time for us to make the investment. After 500,000 users and acceptance into the US Department of Defense, we realized we needed more performance, simpler infrastructure, and guaranteed referential integrity. The move to Postgres gave us all those things and more. However, it wasn’t without a few stress-inducing moments of downtime.
Zero downtime
Even though our app doesn’t receive much usage during the weekends, we architected a zero-downtime migration in order to better support our customers. This meant that we had built-in intermediary steps where the application wrote to both databases at the same time. While this strategy is exponentially more complex than simply taking down the site for a few hours and popping up a new version that uses the new database, it meant that errors were easy to find and data could be verified. For example, by writing to both databases at once, we could compare the contents of the old database and the new one. Any discrepancies could be identified and the root causes could be fixed before we sunsetted the old database. This incremental migration pattern also allowed other developers to continue their work while the migration was taking place.
Squashing bugs
So where did we goof up? Particularly where it comes to referential integrity. That’s the link between two objects in a database, such as all the teams a user is on. If we create a team member before the team gets created, we’re going to hit an error. Hitting that error is good! It means no more orphaned teams. However, in a system where lots of work is done in parallel, we found that sometimes there would be race conditions and under certain conditions, users couldn’t create a new team (that was me, sorry about that!).
The majority of these bugs were caught in local testing, or QA testing in a pre-production environment. However, there were some that made it all the way to production. For example, there was the missing table index that made for an expensive query that locked up an entire table. That’s why we also set up tracing to monitor which database queries were taking the most time. Additionally, we put in error handling & closely monitored new issues that had never been seen before. If a new issue cropped up within 24 hours of a deployment, we were quick to investigate and push out a hotfix if needed.
Backend maturity = stability & performance
In the end, we have a product that’s faster, more stable, and easier to set up for our self-hosted customers. Some paginated queries dropped from 250ms to 50ms, a pretty big deal in the tech world! We could also stop maintaining the RethinkDB image within the DoD’s IronBank, which made our infrastructure team happy.
As we look towards the future, we’ve learned quite a bit. The biggest lesson learned is that the further back the stack, the more boring the technology should be. Front-end animations? Try that new package that everyone is talking about. Database and DevOps? Make sure it’s been battle tested for a few years.
Metrics
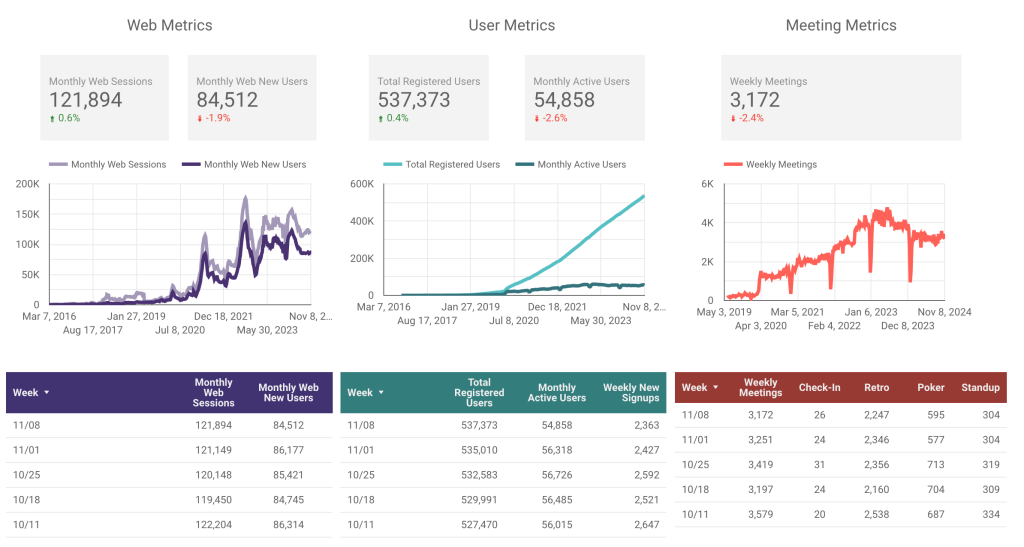
Metrics were a little soft this week. However, we expect to start seeing a number of end-of-year retrospectives and planning activities for next year. Folks are writing into Customer Success asking about the best activities to achieve this. As the year comes to a close we’ll be doing the same ourselves!
This week we…
…held our quarterly Board of Directors call. We greatly appreciate the feedback and support we get from this team when sharing about our successes, challenges, and opportunities ahead.
…spent some time shaping up improvements and new activities for our software. We’ve had a lot of feedback and done a great deal of research on what activities to better support. We look forward to sharing more during our next demo.
…followed up with several partners and potential customers from the TechNet trade show. It’s great to be able to continue the conversations we started a few weeks back in Hawaii. We’re very excited about some upcoming developments! Stay tuned
…released some quality of life updates to the app. We’ve shipped a steady stream of fixes and small improvements to our software lately.
Next week we’ll…
…wrap up week 3 of our current Shape Up cycle. We’re almost halfway through the current Shape Up development cycle. We look forward to our midway demo.
Have feedback? See something that you like or something you think could be better? Please write to us.
